
Within embedded vision systems, object detection and classification algorithms stand as pillars of innovation, and rightly so. These algorithms possess the remarkable ability to decipher the visual world. This capability enables machines to perceive, interpret, and respond to their surroundings with unprecedented precision.
Consider a world where security cameras not only observe but also actively identify potential threats. Or imagine a situation where autonomous vehicles seamlessly navigate complex traffic scenarios with ease – without any assistance from humans. These are just two of the many ways in which object detection and classification algorithms are revolutionizing industries and reshaping our daily lives.
From enhancing public safety to optimizing transportation systems, the applications of these algorithms are as diverse as they are impactful. In this blog post, we embark on a captivating journey into the heart of this groundbreaking technology.
Object Identification Technology
Object Detection and Classification Algorithms
Object detection and classification algorithms have brought a new dimension to embedded vision systems. Some of the popular algorithms in this domain include:
Histogram of Oriented Gradients (HOG)
The Histogram of Oriented Gradients (HOG) is a classic feature extraction technique widely used in object detection and classification tasks. HOG operates by computing the gradient magnitude and orientation of image pixels within localized regions, known as cells. These gradient histograms capture information about the local edge and texture patterns present in the image, encoding important visual cues for object recognition.
Despite its simplicity, HOG remains a powerful tool for detecting objects with well-defined edge and texture patterns, making it particularly suitable for tasks such as pedestrian detection, face recognition, and vehicle detection.
Region-based Convolutional Neural Networks (R-CNN)
The Region-based Convolutional Neural Network (R-CNN) family of algorithms represents a groundbreaking advancement in object detection. Introduced by Ross Girshick et al., R-CNN and its variants, including Fast R-CNN and Faster R-CNN, pioneered the use of region proposal methods combined with CNNs for object detection tasks.
R-CNN
The original R-CNN approach marked a significant advancement in object detection by introducing a multi-stage pipeline. It started with a selective search algorithm generating region proposals, which were then individually classified using a CNN.
Despite its effectiveness in identifying objects, this approach had significant drawbacks. Its reliance on external region proposal methods made it computationally intensive and inefficient. Processing each region separately resulted in redundant computations and slow inference speeds, limiting its practical utility in real-time applications.
Fast R-CNN
To address the limitations of R-CNN, Fast R-CNN introduced several key innovations that dramatically improved both speed and efficiency. The key breakthrough was the introduction of Region of Interest (RoI) pooling, a technique that allowed feature extraction to be performed on the entire image rather than individual proposals.
By pooling features from the entire image, Fast R-CNN eliminated the need for redundant computations and significantly accelerated the detection process. This approach also enabled end-to-end training of the network, further enhancing its performance and robustness.
Faster R-CNN
Building upon the success of Fast R-CNN, Faster R-CNN further optimized the object detection pipeline by integrating the region proposal generation directly into the network architecture. Instead of relying on external algorithms for region proposals, Faster R-CNN introduced a Region Proposal Network (RPN) that learned to generate region proposals directly from feature maps.
Faster R-CNN achieved state-of-the-art performance in terms of both accuracy and speed. This integrated approach not only streamlined the detection pipeline but also improved the overall efficiency of the system, making it suitable for real-time applications.
Single Shot Detector (SSD)
Single Shot Detector (SSD) represents a significant advancement in object detection algorithms, particularly in terms of real-time performance and accuracy. Unlike traditional two-stage approaches like R-CNN, SSD adopts a single-stage architecture, enabling it to simultaneously predict object bounding boxes and class probabilities directly from feature maps at multiple scales.
This streamlined approach eliminates the need for separate region proposal and classification stages, resulting in faster inference speeds and reduced computational complexity. SSD achieves robust object detection across a wide range of object sizes and aspect ratios. This makes it well-suited for real-time applications such as autonomous driving, surveillance, and robotics.
You Only Look Once (YOLO)
You Only Look Once (YOLO) is a groundbreaking object detection algorithm known for its simplicity, speed, and accuracy. It was introduced in 2016 by Joseph Redmon, Santosh Divvala, Ross Girshick, and Ali Farhadi. YOLOv8 is the latest version of the algorithm, which merges high performance and accuracy in object detection.
YOLO takes a unified approach by directly predicting bounding boxes and class probabilities from a single neural network. As mentioned earlier, YOLO achieves real-time performance without sacrificing accuracy. This is made possible by dividing the input image into a grid and predicting bounding boxes and class probabilities for each grid cell. This allows YOLO to process images extremely quickly, making it ideal for applications where speed is paramount. Real-time surveillance, video analysis, and autonomous navigation are examples of such applications.
Spatial Pyramid Pooling (SPP-net)
Spatial Pyramid Pooling (SPP-net) is a pioneering approach in object detection that addresses the challenge of handling images with varying sizes and aspect ratios. Traditional convolutional neural networks (CNNs) require fixed-size input images, making them unsuitable for handling images of arbitrary sizes.
SPP-net overcomes this limitation by introducing a spatial pyramid pooling layer, which allows the network to effectively process images of different sizes and aspect ratios. The input feature map is divided into a grid of spatial bins with max pooling performed within each bin. This helps generate fixed-size feature vectors regardless of the input image size. This enables the network to achieve scale-invariant object detection, making it highly effective in scenarios where objects may appear at different scales within an image.
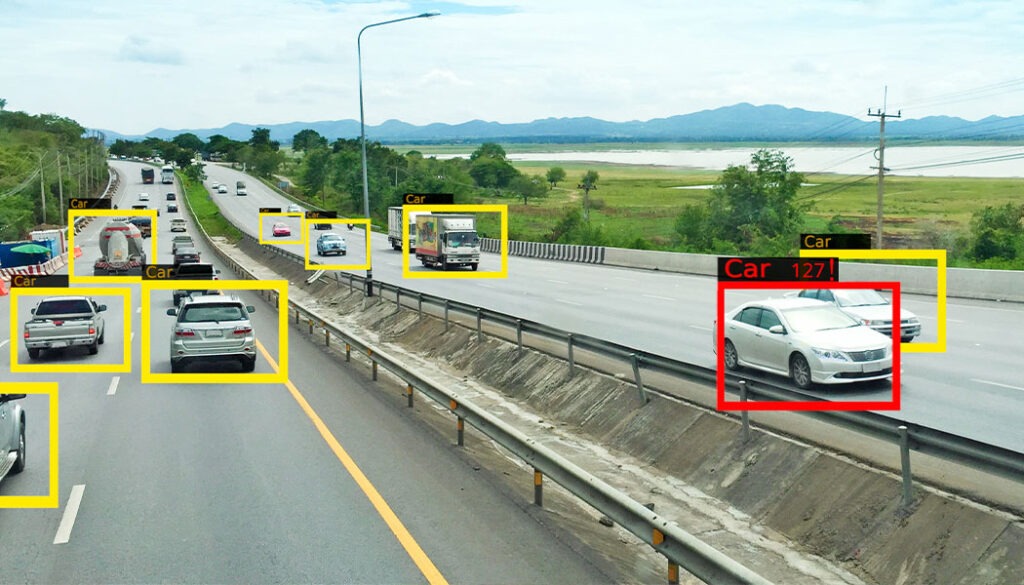
How Cameras Enable Object Detection

Object Detection in Smart Traffic Systems
Embedded cameras play a vital role in enabling object detection by capturing high-quality images used as input for detection algorithms. These cameras come in various forms, including both 2D and 3D variants, each offering unique advantages for different applications. High-quality imaging is paramount to ensure accurate detection and classification of objects within the captured scenes.
Additionally, in scenarios requiring comprehensive coverage or depth perception, multi-camera setups are often employed to provide a more detailed and robust understanding of the environment.
From monitoring traffic flow on roads to detecting anomalies in industrial settings and enabling smart surveillance systems, embedded cameras serve as the eyes of object detection systems, capturing the visual data necessary for intelligent decision-making.
Popular Embedded Vision Applications Where Object Detection and Classification Are Used
Some popular applications where object detection and classification technologies are widely used include:
Autonomous Shopping
Autonomous shopping experiences, such as cashier-less stores, rely heavily on object detection and classification algorithms to track customer interactions with products. Embedded cameras strategically placed throughout the store capture real-time video footage of shoppers and the items they select.
Advanced computer vision algorithms analyze this footage to identify and classify products, enabling seamless checkout experiences without the need for traditional cashiers or checkout counters.
Amazon Go stores utilize object detection and classification to enable autonomous shopping experiences. Embedded cameras track customers as they pick up items, while algorithms identify the products and automatically charge the customer upon exiting the store.
Harvesting Robot
In agriculture, harvesting robots equipped with embedded cameras leverage object detection and classification algorithms to automate the process of picking fruits and vegetables. Embedded cameras on these robots capture images of crops in real-time. On the other hand, advanced algorithms analyze the images to identify ripe produce ready for harvest.
The harvesting robots can efficiently navigate through fields and perform selective harvesting tasks by precisely detecting and classifying fruits or vegetables based on size, color, and ripeness.
The Strawberry-Picking Robot developed by Harvest CROO Robotics employs object detection to identify ripe strawberries. Embedded cameras capture images of the fruit, while algorithms analyze them to determine ripeness, enabling the robot to selectively harvest ripe strawberries with precision.

A harvesting robot
Digital Liquid Handling Systems
In laboratories and research facilities, digital liquid handling systems utilize object detection and classification algorithms to automate the process of fluids and samples management. Embedded cameras integrated into these systems capture images of liquid-filled containers and samples, while advanced vision algorithms analyze the images to detect and classify various components.
With accurate object identification – like test tubes, pipette tips, and liquid volumes – these systems can automate complex laboratory workflows, including sample preparation, assay assembly, and drug discovery processes.
The Opentrons OT-2 liquid handling robot utilizes object detection and classification to automate laboratory workflows. Embedded cameras identify labware and liquid volumes, allowing the robot to accurately dispense fluids for various experiments and assays.
Further Reading: Digitizing Laboratory Equipment with Embedded Cameras
Product Sorting in Factory Automation
Factory automation systems rely on object detection and classification algorithms to streamline the process of sorting and categorizing products on assembly lines. Embedded cameras installed along conveyor belts capture images of moving objects, while intelligent algorithms analyze the images to identify products based on predefined criteria such as size, color, and defects.
This ensures that each product is routed to the appropriate destination for further processing or packaging. This, in turn, enhances manufacturing efficiency, minimizes errors, and improves overall product quality control.
Bug and Weed Detection
In agriculture, embedded vision systems are used for pest management and weed detection in fields. Mounted on drones or agricultural vehicles, embedded cameras capture high-resolution images of crops, while object detection algorithms analyze the images to identify and classify pests, diseases, or weeds.
Farmers can implement targeted interventions, such as pesticide application or weed removal, to mitigate crop damage and improve yield outcomes. This proactive approach to pest and weed management enhances agricultural productivity, reduces chemical usage, and promotes sustainable farming practices.
Blue River Technology’s See & Spray precision agriculture system employs object detection to identify weeds in crop fields. Mounted on agricultural vehicles, embedded cameras capture images of crops, while algorithms analyze them to detect and classify weeds. This enables targeted herbicide application, reducing chemical usage and improving crop yields.
TechNexion – AI-ready Cameras for Embedded Vision Systems
TechNexion’s AI-ready cameras are tailored for embedded vision systems – delivering high-quality images essential for AI and ML algorithm analysis. With multi-camera support, our cameras meet the crucial requirement of AI-based vision systems. This enables simultaneous operation of multiple cameras for comprehensive scene analysis and enhanced accuracy in object detection and classification.
Another feature of TechNexion cameras is the built-in image signal processor (ISP), which offloads the host processor from many image processing steps, avoids the need for separate tuning, and makes images available to the application layer that are immediately ready for AI inference processing.
Whether deployed in autonomous vehicles, smart surveillance systems, or industrial automation, TechNexion’s cameras empower embedded vision applications with robust performance and seamless integration. Contact us to know more about how our AI-ready cameras can elevate your embedded vision projects.
Related Products



Get a Quote
Fill out the details below and one of our representatives will contact you shortly.